Data pipeline memastikan setiap informasi, mulai dari data transaksi hingga interaksi pengguna, dapat mengalir secara efisien dan otomatis. Tanpa alur kerja yang terstruktur ini, seorang data science, developer pengambilan keputusan penting bisa terhambat oleh data yang berantakan dan tidak konsisten.
Melalui panduan ini, kita akan memahami cara kerja, komponen penting, serta berbagai jenis pipeline yang menjadi andalan dalam industri teknologi saat ini.
Apa itu Data Pipeline?
Secara sederhana, data pipeline adalah serangkaian proses terotomatisasi yang memindahkan data dari satu sistem ke sistem lainnya.
Sebuah data pipeline memindahkan data dari satu sistem ke sistem lain melalui serangkaian proses yang terotomatisasi. Proses ini mencakup tahapan:
- ekstraksi (pengambilan)
- transformasi (pemrosesan)
- hingga penyimpanan (storage) di lokasi tujuan.
Tujuan utamanya untuk mengubah data mentah dari berbagai sumber menjadi informasi yang terstruktur dan siap guna.
Dalam dunia bisnis, pipeline berfungsi sebagai “jalan tol” data yang memastikan aliran informasi berjalan cepat dan konsisten untuk analisis, pelaporan, atau kebutuhan operasional lainnya, seperti yang dijelaskan oleh Amazon Web Services.
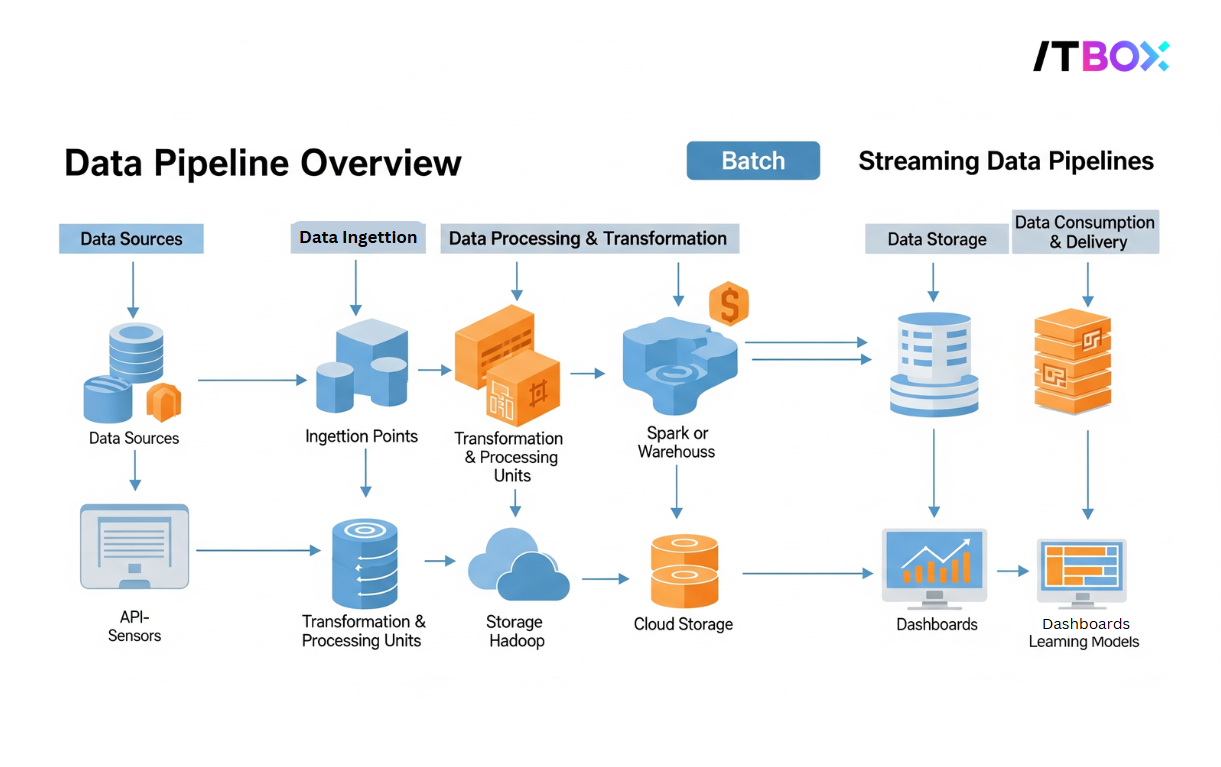
Manfaat dari Data Pipeline
Dengan menerapkan data pipeline yang efektif, sebuah organisasi dapat memperoleh keuntungan signifikan sebagai berikut:
- Meningkatkan Kualitas Data
Pipeline secara otomatis membersihkan, memvalidasi, dan mengubah format data sebelum sampai ke tujuan. Ini membantu menghilangkan data duplikat, tidak relevan, atau rusak. - Efisiensi Pemrosesan Data
Proses manual yang memakan waktu dan rentan human error dapat dihilangkan. Pipeline mempercepat seluruh siklus kerja data secara otomatis dan terstandar. - Integrasi Data Komprehensif
Memungkinkan data dari berbagai sumber (seperti big database, API, atau layanan cloud) digabungkan. Hasilnya memberikan pandangan 360 derajat yang utuh untuk analisis bisnis. - Fleksibilitas dan Skalabilitas
Pipeline yang dirancang dengan baik bersifat modular. Anda dapat dengan mudah menambah sumber data baru, mengubah proses transformasi, atau mengganti tujuan penyimpanan tanpa harus membangun sistem dari awal.
Komponen Utama Data Pipeline
Dengan mengetahui struktur dasar ini, Anda dapat merancang sistem pipeline yang efisien, terukur, dan sesuai dengan kebutuhan bisnis maupun teknis. Berikut adalah elemen-elemen utama yang harus ada dalam sebuah pipeline data.
1. Data Source
Merupakan titik awal data, bisa berupa sensor, aplikasi, database internal, atau sumber eksternal seperti API.
2. Ingestion
Tahap ini bertugas “mengambil” data dari sumbernya, baik secara batch (berkala) atau real-time (langsung).
3. Processing
Data diproses sesuai kebutuhan: dibersihkan, diformat ulang, di filter, atau dikombinasikan. Proses ini bisa berlangsung secara real-time maupun setelah data dikumpulkan.
4. Storage
Data yang telah diproses disimpan dalam storage yang sesuai, seperti data warehouse, data lake, atau database relasional.
5. Workflow Management
Mengatur dan memantau jalannya pipeline, memastikan tahapan berjalan lancar dan memberi notifikasi jika terjadi kegagalan.
6. Data Output & Consumption
Data siap digunakan untuk analitik, visualisasi, dashboard, atau aplikasi bisnis lainnya.
Memahami setiap komponen ini adalah langkah awal yang solid. Untuk mulai mempraktikkan cara membangun logikanya dari dasar, Anda bisa memulainya dengan mempelajari struktur data di kelas Basic Python untuk Data Science.
Jenis-Jenis Data Pipeline
Berikut beberapa jenis pipeline data yang paling umum digunakan saat ini.
1. Batch Pipeline
Memproses data dalam kelompok besar pada interval tertentu. Cocok untuk laporan keuangan bulanan atau data penjualan harian.
- Penggunaan: Paling cocok untuk proses bisnis yang tidak sensitif terhadap waktu, seperti pelaporan (reporting) periodik, analisis data historis, dan sinkronisasi data antar sistem di luar jam kerja.
- Contoh Spesifik: Sebuah bank mengumpulkan semua data transaksi harian untuk diproses menjadi laporan keuangan pada tengah malam.
2. Real-time Pipeline
Memproses data langsung saat diterima. Umumnya digunakan dalam sistem notifikasi, pemantauan jaringan, atau e-commerce yang membutuhkan respons instan.
- Penggunaan: Krusial untuk sistem yang membutuhkan respons instan, seperti pemantauan (monitoring) sistem, deteksi anomali (fraud detection), personalisasi konten live, dan pemrosesan transaksi online.
- Contoh Spesifik: Pada platform ride-hailing, data lokasi pengemudi terus diproses untuk menampilkan posisinya di peta pengguna secara live.
3. ETL (Extract, Transform, Load)
Mengambil data dari sumber, melakukan transformasi, lalu menyimpan ke tujuan. Pendekatan ini baik untuk skenario di mana data perlu dibersihkan sebelum disimpan.
- Penggunaan: Umumnya dipakai dalam lingkungan business intelligence (BI) tradisional di mana data harus sesuai dengan skema yang ketat di data warehouse untuk keperluan laporan analitik yang terstruktur.
- Contoh Spesifik: Perusahaan ritel menyamakan format data penjualan dari semua cabang (Transform) sebelum memasukkannya ke data warehouse pusat untuk analisis performa nasional (Load).
4. ELT (Extract, Load, Transform)
Kebalikan dari ETL, data dimuat terlebih dahulu ke penyimpanan, baru kemudian diproses. Cocok untuk sistem modern seperti data lake yang menyimpan data dalam bentuk mentah terlebih dahulu.
- Penggunaan: Ideal untuk skenario big data dan data science di mana fleksibilitas analisis lebih diutamakan. Ini memungkinkan semua data mentah dikumpulkan terlebih dahulu di data lake agar bisa dieksplorasi untuk berbagai tujuan di kemudian hari.
- Contoh Spesifik: Platform media sosial memuat semua data mentah (klik, likes) ke data lake (Load), baru kemudian tim data science melakukan transformasi sesuai kebutuhan riset mereka (Transform).
5. Hybrid Pipeline
Menggabungkan beberapa jenis pipeline sesuai kebutuhan. Contohnya menggabungkan batch untuk laporan keuangan dan real-time untuk pelacakan pengiriman barang.
- Penggunaan: Digunakan oleh hampir semua perusahaan skala besar yang memiliki kebutuhan bisnis beragam, di mana sebagian memerlukan kecepatan real-time dan sebagian lagi cukup dengan efisiensi proses batch.
- Contoh Spesifik: Perusahaan e-commerce memakai real-time pipeline untuk rekomendasi produk, sekaligus batch pipeline setiap malam untuk menghitung stok barang.
Memilih jenis pipeline yang tepat bergantung pada kebutuhan proyek. Jika Anda ingin mendalami setiap pendekatan ini secara komprehensif bersama praktisi ahli, materi di Fundamental Data Science Complete Series akan memandu Anda.
Belajar Data Science Lebih Dalam di Kursus ITBOX
Memahami data pipeline adalah langkah krusial untuk siapa pun yang bekerja di bidang data. Keterampilan ini tidak hanya meningkatkan efisiensi, tetapi juga membuka jalan untuk inovasi dan pengambilan keputusan yang lebih cerdas.
Siap mengambil langkah selanjutnya? Jika Anda memulai dari nol, Kursus Basic Python untuk Data Science dari ITBOX adalah titik awal yang sempurna.
Bagi Anda yang ingin menguasai keseluruhan proses secara mendalam, program Fundamental Data Science Complete Series akan membekali Anda dengan keahlian yang dicari in