Pernahkah kamu penasaran bagaimana aplikasi di ponsel kamu bisa dengan akurat mengidentifikasi wajah kamu atau bagaimana layanan streaming musik dapat merekomendasikan lagu-lagu yang kamu suka? Di balik keajaiban teknologi ini, terdapat model-model klasifikasi yang berperan penting.
Model klasifikasi adalah algoritma yang dilatih untuk mengelompokkan data ke dalam kategori-kategori tertentu. Misalnya, model klasifikasi dapat digunakan untuk mengklasifikasikan gambar menjadi kucing atau anjing, atau mendeteksi adanya penipuan dalam transaksi keuangan.
Namun, bagaimana kita bisa memastikan bahwa model-model ini memberikan hasil yang akurat? Confusion matrix adalah salah satu alat yang paling umum digunakan untuk mengevaluasi kinerja model klasifikasi dan membantu kita memahami seberapa baik model tersebut dalam membuat prediksi.
Baca Juga: Mengenal Machine Learning, Tipe & Contoh Penggunaannya
Daftar Isi Artikel
ToggleMemahami Confusion Matrix
Confusion matrix adalah sebuah tabel yang menyajikan perbandingan antara prediksi model dengan nilai aktual. Dengan menggunakan confusion matrix, kita dapat menghitung berbagai metrik evaluasi seperti akurasi, precision, recall, dan F1-score untuk menilai kinerja model secara menyeluruh.
Definisi Apa itu Confusion Matrix
Confusion matrix adalah sebuah tabel yang sangat penting dalam mengukur kinerja dari suatu model klasifikasi dalam machine learning. Tabel ini menampilkan perbandingan antara hasil prediksi model dengan nilai aktual dari data.
Dengan kata lain, confusion matrix mengungkapkan seberapa baik model kita dalam memprediksi suatu kelas tertentu, misalnya apakah seorang pasien terkena kanker atau tidak.
Komponen Confusion Matrix:
Confusion matrix terdiri dari beberapa komponen utama yang menjelaskan tingkat keberhasilan dan kesalahan model kita dalam melakukan prediksi. Komponen-komponen tersebut adalah:
- True Positive (TP): Jumlah data yang diprediksi positif oleh model dan kenyataannya memang positif. Misalnya, model memprediksi seorang pasien terkena kanker dan hasil tes medis menunjukkan bahwa pasien tersebut memang sakit kanker.
- True Negative (TN): Jumlah data yang diprediksi negatif oleh model dan kenyataannya memang negatif. Misalnya, model memprediksi seorang pasien tidak terkena kanker dan hasil tes medis menunjukkan bahwa pasien tersebut memang sehat.
- False Positive (FP): Jumlah data yang diprediksi positif oleh model tetapi kenyataannya negatif. Ini sering disebut sebagai “false alarm”. Misalnya, model memprediksi seorang pasien terkena kanker, namun setelah pemeriksaan lebih lanjut ternyata pasien tersebut sehat.
- False Negative (FN): Jumlah data yang diprediksi negatif oleh model tetapi kenyataannya positif. Ini adalah jenis kesalahan yang sangat berbahaya dalam beberapa kasus, seperti pada diagnosis medis. Misalnya, model memprediksi seorang pasien tidak terkena kanker, padahal pasien tersebut sebenarnya sakit kanker.
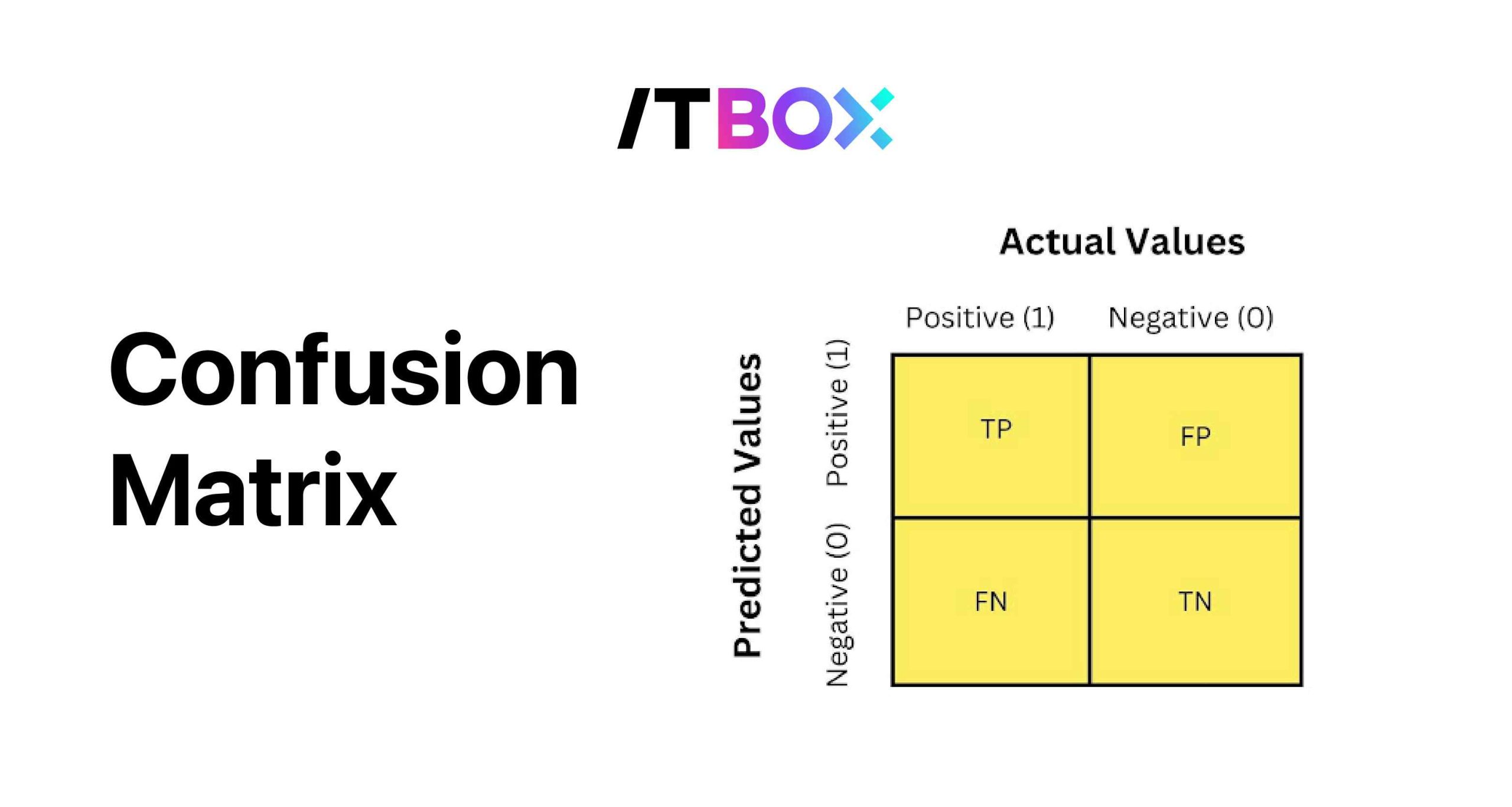
Visualisasi Confusion Matrix: Contoh visualisasi confusion matrix.
Confusion matrix biasanya divisualisasikan dalam bentuk tabel sederhana dengan dua baris dan dua kolom. Setiap sel dalam tabel menunjukkan jumlah data yang termasuk dalam masing-masing kategori (TP, TN, FP, FN).
Visualisasi ini membantu kita untuk memahami dengan mudah kinerja model dan mengidentifikasi jenis kesalahan yang sering terjadi.
Metrik Evaluasi dari Confusion Matrix
Dalam konteks evaluasi model klasifikasi, confusion matrix memberikan informasi yang sangat berguna untuk menghitung berbagai metrik evaluasi yang dapat membantu kita memahami kinerja model. Berikut adalah beberapa metrik evaluasi utama yang dapat diperoleh dari confusion matrix:
Accuracy
Accuracy atau tingkat akurasi adalah proporsi dari prediksi yang benar dibandingkan dengan total jumlah prediksi. Metrik ini memberikan gambaran umum tentang seberapa baik model dalam melakukan klasifikasi. Rumusnya adalah:
[ \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} ]
di mana TP adalah True Positives, TN adalah True Negatives, FP adalah False Positives, dan FN adalah False Negatives. Meskipun akurasi adalah metrik yang mudah dipahami, ia bisa menyesatkan jika dataset tidak seimbang.
Precision
Precision mengukur proporsi prediksi positif yang benar. Ini penting ketika biaya dari kesalahan positif (false positive) tinggi. Precision memberikan gambaran tentang seberapa tepat model dalam mengidentifikasi kelas positif. Rumusnya adalah:
[ \text{Precision} = \frac{TP}{TP + FP} ]
Dengan kata lain, precision menunjukkan seberapa banyak dari semua prediksi positif yang benar-benar positif.
Recall (Sensitivity)
Recall, juga dikenal sebagai sensitivitas, mengukur proporsi instance positif yang benar-benar diklasifikasikan sebagai positif. Metrik ini sangat penting dalam situasi di mana kita ingin meminimalkan jumlah false negatives. Rumusnya adalah:
[ \text{Recall} = \frac{TP}{TP + FN} ]
Recall memberikan informasi tentang seberapa baik model dalam menemukan semua instance positif yang ada.
Specificity
Specificity mengukur proporsi instance negatif yang benar-benar diklasifikasikan sebagai negatif. Metrik ini penting dalam konteks di mana kita ingin meminimalkan jumlah false positives. Rumusnya adalah:
[ \text{Specificity} = \frac{TN}{TN + FP} ]
Specificity membantu kita memahami seberapa baik model dalam mengidentifikasi kelas negatif.
F1-Score
F1-Score adalah kombinasi harmonik dari precision dan recall. Metrik ini berguna ketika kita perlu mempertimbangkan kedua metrik tersebut secara bersamaan, terutama dalam situasi di mana ada trade-off antara precision dan recall. F1-Score memberikan ukuran tunggal yang mencerminkan keseimbangan antara keduanya. Rumusnya adalah:
[ F1\text{-Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} ]
Dengan menggunakan F1-Score, kita dapat mengevaluasi kinerja model dengan lebih baik, terutama ketika ada ketidakseimbangan antara kelas positif dan negatif.
Contoh Penerapan Confusion Matrix
Confusion matrix tidak hanya sekedar konsep teoritis, tetapi memiliki aplikasi yang sangat luas dalam berbagai bidang. Mari kita bahas dua contoh penerapan confusion matrix yang sering ditemui:
Kasus Klasifikasi Spam: Membedakan Antara Email yang Berguna dan Sampah
Dalam kasus klasifikasi email spam, kelas positif dapat didefinisikan sebagai email spam dan kelas negatif sebagai email yang bukan spam. Confusion matrix akan menunjukkan seberapa baik model kita dalam mengklasifikasikan email baru sebagai spam atau bukan spam.
Nilai false positive yang tinggi berarti model kita sering kali menandai email yang bukan spam sebagai spam, yang dapat mengganggu produktivitas pengguna.
Kasus Deteksi Penyakit: Mendiagnosis Penyakit dengan Akurat
Dalam bidang medis, confusion matrix digunakan untuk mengevaluasi kinerja model dalam mendiagnosis penyakit. Misalnya, dalam kasus deteksi kanker, kelas positif adalah pasien yang memiliki kanker dan kelas negatif adalah pasien yang tidak memiliki kanker.
Nilai false negative yang tinggi dalam kasus ini memiliki konsekuensi yang sangat serius karena pasien yang seharusnya mendapat perawatan tidak akan mendapat diagnosis yang tepat.
Interpretasi Hasil Confusion Matrix
Confusion matrix memberikan kita lebih dari sekadar angka akurasi. Dengan memahami berbagai metrik yang dapat dihitung dari confusion matrix, kita dapat menginterpretasikan hasil secara mendalam dan mengambil keputusan yang lebih baik terkait dengan penerapan model dalam dunia nyata.
Trade-off antara Precision dan Recall
Ketika kita berbicara tentang precision dan recall, kita sebenarnya sedang melihat trade-off di antara keduanya. Precision mengukur seberapa tepat model dalam memprediksi kelas positif, sedangkan recall mengukur kemampuan model dalam menghasilkan semua kelas positif yang benar.
Contohnya, dalam kasus sepak bola, precision bisa menggambarkan seberapa sering model memprediksi kemenangan dengan benar, sementara recall mengukur seberapa sering model bisa mendeteksi semua kemenangan.
Terkadang, meningkatkan precision bisa menghasilkan penurunan recall, dan sebaliknya, tergantung pada dataset dan langkah optimasi yang diambil.
Choosing the Right Metric
Memilih metrik yang tepat sangat tergantung pada tujuan bisnis. Dalam kasus sepak bola, jika model digunakan untuk mendeteksi kemenangan tim, recall mungkin lebih penting daripada precision karena kita ingin memastikan semua potensi kemenangan terdeteksi.
Namun, jika fokus pada pengurangan kesalahan prediksi kemenangan, precision mungkin lebih penting. Metrik seperti F1-score, yang menggambarkan keseimbangan antara precision dan recall, juga bisa dipertimbangkan.
Implementasi Confusion Matrix dalam Python
Dalam implementasi confusion matrix dengan Python, kita bisa menggunakan library Scikit-learn, yang memiliki fungsi yang sangat lengkap untuk menghasilkan matriks dan metrik evaluasi lainnya. Contoh di bawah ini menunjukkan bagaimana kita bisa menghitung confusion matrix dengan dataset yang kita miliki:
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# Load dataset
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=11)
# Train model
model = RandomForestClassifier(random_state=1)
model.fit(X_train, y_train)
# Prediksi dengan data uji
y_pred = model.predict(X_test)
# Confusion matrix
cm = confusion_matrix(y_test, y_pred)
print(“Confusion Matrix:”)
print(cm)
Classification report
print(“\nClassification Report:”)
print(classification_report(y_test, y_pred))
Dalam contoh ini, dataset Iris digunakan sebagai ilustrasi untuk menggambarkan bagaimana confusion matrix bekerja pada data uji. Penjelasan ini memberikan panduan langkah demi langkah dari pemisahan data uji hingga evaluasi model. Model menghasilkan matriks yang dapat dianalisis lebih lanjut.
Garis evaluasi seperti nilai akurasi dan metrik lain seperti precision dan recall juga akan disajikan dalam laporan klasifikasi.
Baca Juga: Python Adalah : Apa Itu Python, Cara Download, Keunggulan, dan Tipe Datanya
Pentingnya Confusion Matrix: Menekankan pentingnya confusion matrix dalam evaluasi model klasifikasi.
Dalam dunia machine learning, evaluasi model merupakan langkah krusial untuk memastikan kinerja model yang optimal. Confusion matrix hadir sebagai alat yang sangat berharga dalam mengevaluasi model klasifikasi.
Dengan memahami berbagai metrik yang disediakan oleh confusion matrix, kita dapat memperoleh gambaran yang komprehensif tentang kekuatan dan kelemahan model.
Confusion matrix tidak hanya membantu kita mengukur akurasi secara keseluruhan, tetapi juga mengidentifikasi jenis kesalahan yang sering terjadi. Dengan demikian, kita dapat melakukan perbaikan pada model untuk meningkatkan performanya.
Ingin memperdalam pemahaman Kamu tentang confusion matrix dan teknik evaluasi model lainnya? ITBOX menawarkan berbagai kursus data science online yang akan membantu Kamu menguasai keterampilan yang dibutuhkan untuk menjadi seorang data scientist yang handal.
- Kamu bisa belajar di mana saja dengan fleksibel melalui video pembelajaran mandiri.
- Video-video pembelajarannya disusun dengan baik dan mudah dipahami.
- Tersedia forum diskusi untuk bertukar pikiran.
- Bagi yang memilih paket lengkap, tersedia fasilitas konsultasi 1 kali setiap bulan selama satu bulan.
Jangan lewatkan kesempatan untuk meningkatkan kemampuan membangun model machine learning Kamu. Daftar sekarang di Model Machine Learning Dasar ITBOX