
Pernah mendengar tentang confusion matrix alias matriks kebingungan? Jika Anda baru mulai mempelajari bidang data, ini akan membantu Anda melihat jenis prediksi mana yang benar dan salah.
Pada artikel berikut ini akan dibahas konsep confusion matrix, istilah-istilahnya, cara pemakaian, kesalahan umum, serta tips praktis yang bisa langsung diterapkan.
Apa Itu Confusion Matrix?
Dalam berbagai bidang, model dibuat untuk menilai risiko, memfilter spam, memprediksi churn, bahkan membaca citra medis. Namun, setelah model dilatih, pertanyaannya adalah, seberapa baik performanya di dunia nyata? Di sinilah peran confusion matrix.
Singkatnya, confusion matrix adalah tabel evaluasi yang digunakan untuk mengetahui kinerja model pada data uji yang hasilnya sudah diketahui.
Dengan membaginya ke empat kategori (TP, TN, FP, FN), kita bisa menghitung metrik turunan dan memahami kelemahan model secara spesifik, bukan sekadar mengetahui akurasi sekian persen.
Fungsi Confusion Matrix
Confusion matrix digunakan untuk mengevaluasi performa model klasifikasi dalam machine learning. Berikut kegunaan dari confusion matrix.
- Evaluasi prediksi model
Dengan confusion matrix, kita bisa tahu jumlah prediksi yang benar maupun salah, baik untuk kelas positif maupun negatif. Ini membantu melihat performa model secara menyeluruh.
- Dasar pengukuran metrik evaluasi
Matrix ini menjadi dasar untuk menghitung metrik seperti precision, recall, specificity, hingga F1-score.
Semua metrik tersebut penting untuk menilai seberapa baik model bekerja pada kondisi nyata.
- Analisis kesalahan dan perbaikan model
Confusion matrix juga berguna untuk menemukan pola kesalahan dalam machine learning.
Misalnya, model lebih sering salah di kelas tertentu. Informasi ini bisa dipakai untuk melakukan optimasi dan meningkatkan akurasi model.
4 Istilah dalam Confusion Matrix
Agar lebih paham, mari pahami 4 istilah pentingnya berikut ini:
1. True Positive (TP)
Sesuai namanya, ini adalah kasus positif yang terprediksi positif. Contoh: email spam yang dikenali sebagai spam. Semakin tinggi TP, semakin baik kemampuan model menangkap sinyal kelas positif.
2. True Negative (TN)
Sebaliknya, ini adalah kasus negatif yang terprediksi negatif. Contoh: email normal akan dikenali sebagai bukan spam. TN menggambarkan ketenangan model dalam menahan diri agar tidak menandai sesuatu sebagai positif ketika sebenarnya tidak.
3. False Positive (FP)
Karena false (palsu), ini adalah kasus negatif yang salah ditandai positif (Type I Error). Misalnya, klasifikasi transaksi normal yang malah terdeteksi sebagai fraud atau penipuan.
4. False Negative (FN)
Di sisi lain, ini adalah kasus positif yang lolos sebagai negatif (Type II Error). Sebagai contoh di dunia medis, FN lebih berbahaya karena kasus sakit bisa terlewatkan akibat salah deteksi.
Cara Menggunakan Confusion Matrix

Lalu, bagaimana cara menggunakannya? Anda bisa ikuti panduan lengkap berikut ini:
1. Pilih Metode Evaluasi yang Sesuai dengan Tujuan Model
Sebelum menghitung metrik, tentukan tujuannya. Apakah Anda lebih takut salah menuduh (FP) atau takut melewatkan (FN)?
Contohnya, di perbankan, FP (yang menandai transaksi normal sebagai fraud) bisa mengganggu pengalaman pengguna, sehingga presisi penting. Contoh lain di bidang kesehatan, FN bisa berakibat fatal, jadi recall sangat diutamakan.
Dalam hal ini, dari rumus matriks confusion, Anda bisa turunkan metrik:
- Akurasi = (TP + TN) / (TP + TN + FP + FN)
- Presisi = TP / (TP + FP)
- Recall/Sensitivitas = TP / (TP + FN)
- F1-Score = 2 × (Presisi × Recall) / (Presisi + Recall)
Berbagai formulasi di atas merupakan rumus confusion matrix standar.
2. Hindari Overfitting dengan Validasi yang Tepat
Gunakan hold-out atau k-fold cross-validation agar matriks kebingungan yang Anda lihat tidak “terlalu indah” pada data latih saja.
Validasi yang rapi memastikan metrik merefleksikan performa dunia nyata, bukan sekadar menghafal pola.
3. Visualisasi Confusion Matrix untuk Memudahkan Analisis
Plot heatmap membuat pola error terlihat jelas: kelas mana yang sering tertukar, hingga baris mana yang “berat” FN-nya.
Di lingkungan praktis, banyak yang membuat confusion matrix Python dengan scikit-learn lalu memvisualisasikan via Matplotlib/Seaborn. Pendekatan ini mempermudah komunikasi hasil ke tim non-teknis.
4. Gunakan Confusion Matrix pada Berbagai Jenis Data dan Model
Baik untuk klasifikasi biner maupun multi-kelas, matriks confusion tetap relevan. Untuk teks, visi komputer, tabular, atau sinyal, ini bisa memberi peta kesalahan yang konkret.
Nah, kalau Anda mengolah presentasi hasil, pertimbangkan alat bantu seperti Tome App agar mudah menjelaskan temuan ke stakeholder.
Cara Mengukur Performa Confusion Matrix
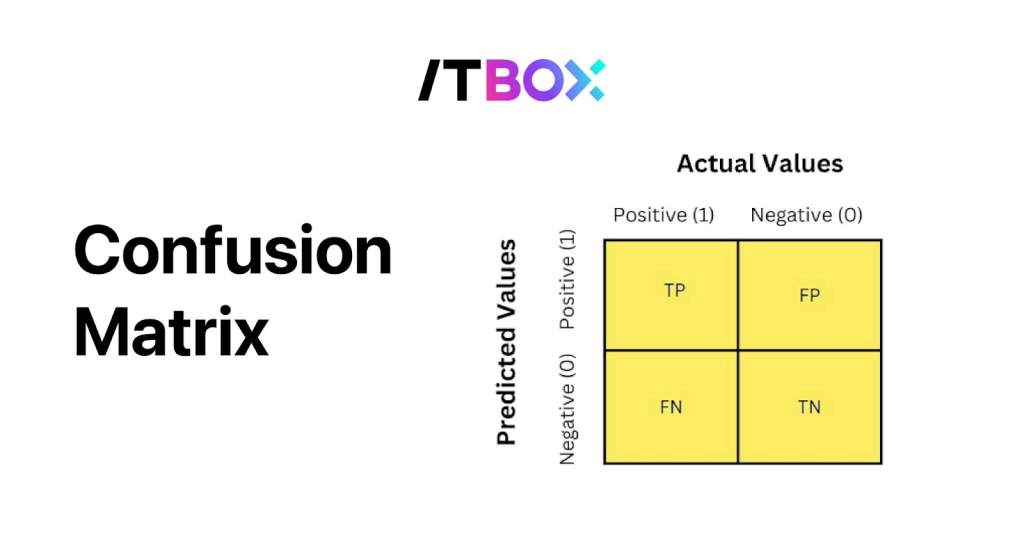
Dari tabel diatas, kita bisa melihat jumlah prediksi benar dan salah, baik pada kelas positif maupun negatif.
1. Akurasi
Akurasi menunjukkan seberapa banyak prediksi yang benar dibandingkan dengan seluruh data. Rumusnya sederhana: prediksi benar dibagi total data.
2. Precision
Precision mengukur ketepatan prediksi positif. Artinya, dari semua data yang diprediksi positif, berapa banyak yang benar-benar positif. Metrik ini penting jika kesalahan prediksi positif membawa risiko besar.
3. Recall
Recall melihat seberapa baik model menemukan semua data positif. Dengan kata lain, dari semua data positif yang ada, berapa banyak yang berhasil ditangkap oleh model.
4. F1-Score
F1-Score adalah gabungan precision dan recall. Nilai ini memberikan keseimbangan, terutama saat kita ingin mengukur performa model secara lebih adil pada data yang tidak seimbang.
Kesalahan yang Umum Terjadi Saat Membaca Confusion Matrix
Lalu, bagaimana caranya agar tidak salah menafsirkan matriks? Perhatikan berbagai hal berikut ini:
1. Tidak Memperhitungkan Ketimpangan Kelas dalam Dataset
Dataset timpang (misal 95% negatif, 5% positif) bisa membuat akurasi menipu. Model selalu menebak “negatif” tetap dapat akurasi tinggi, padahal recall kelas minoritas nol.
2. Mengandalkan Accuracy tanpa Melihat Metrik Lain
Akurasi memang intuitif, tetapi sering tidak cukup. Matriks confusion memaksa kita menengok keseimbangan presisi vs recall dan F1-Score. Di domain berisiko tinggi, F1 atau AUC sering lebih informatif ketimbang akurasi mentah.
3. Salah Menafsirkan False Positive dan False Negative
Perbedaan FP dan FN adalah soal konsekuensi bisnis. Jadi, jangan samakan keduanya. Definisikan biaya kesalahan sejak awal, lalu pilih metrik dan threshold yang selaras. Prinsip ini adalah inti praktik evaluasi yang baik.
Pelajari Model Machine Learning Lebih Dalam di ITBOX
Dengan memahami TP, TN, FP, FN, kita bisa menurunkan metrik seperti akurasi, presisi, recall, dan F1-Score, menilai dampak ketimpangan kelas, menyesuaikan threshold, hingga memandu perbaikan model.Anda dapat mendalami materi-materi dasar tentang machine learning lewat program Fundamental Data Analyst Complete Series dan Basic Python untuk Data Science di ITBOX.




